Image Classification
In a classical Image Classification task, your system receives some input image, such as a picture of a cat. This system is also aware of some predetermined set of labels, such as [cat, dog, truck, plane, taco]. The job of the computer is to look at the picture and assign it to one of these fixed category labels.
To humans, this seems like a really easy problem, because so much of your own visual system in your brain is hardwired to perform these visual recognition tasks. But this is actually a really really hard problem for a machine.
So what does a computer see when it looks at this image of a cat? It definitely doesn't get this holistic idea of a cat that you see when you look at it - the computer really is representing this image as a gigantic grid of numbers.
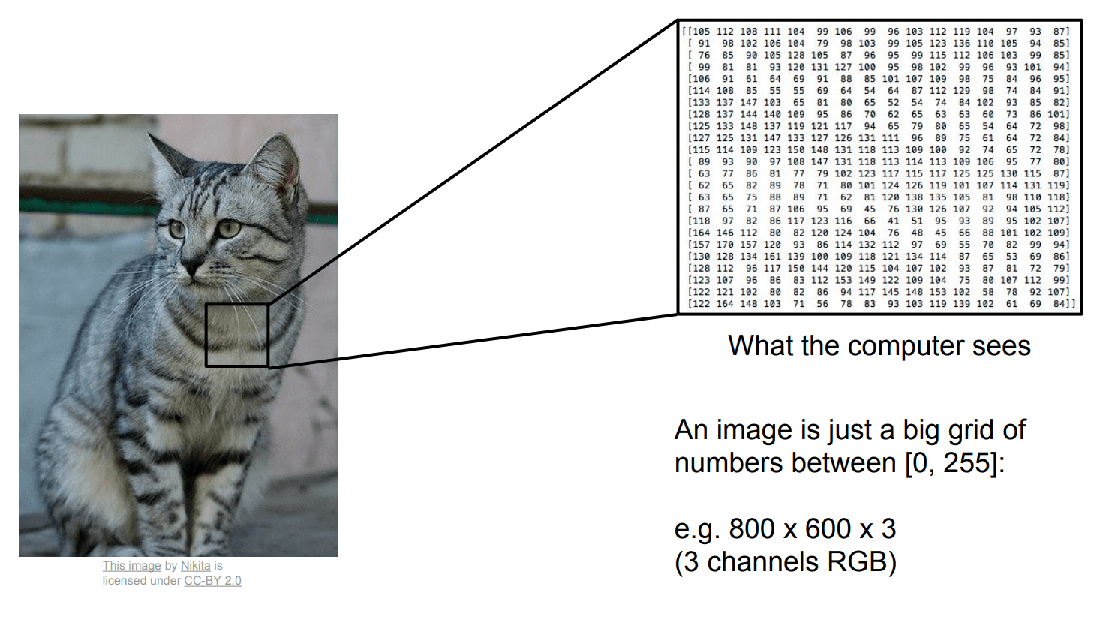
So the input image might be something like 800 x 600 Pixels, and then each pixel is represented by three numbers, giving the Red Green and Blue values for that pixel. And it's very difficult to distill the cat-ness out of this giant array of very many different numbers.
So we refer to this problem as the semantic gap. The idea of a cat, or this label of a cat, is a semantic label that we're assigning to this image, and there's a huge gap between the semantic idea of a cat and this array of pixel values that the computer is actually seeing.